
Google Container day and Kubecon + CloudNativeCon Europe 2026

Opening keynote at Kubecon + CloudNativeCon Europe 2026
Introduction
Last week, I had the opportunity to attend Kubecon + CloudNativeCon Europe in Amsterdam. At this occasion, I was lucky enough to be able to attend Google’s co-organized event “Container Day” the day prior to the event.
Both were packed with insightful sessions that provided a deep dive into the latest hot topics and advancements in cloud-native technologies and Kubernetes.
Google Container Day
Google shared with us a sneak peek at the future of GKE before the official announcements at Google Cloud Next in Las Vegas next month.
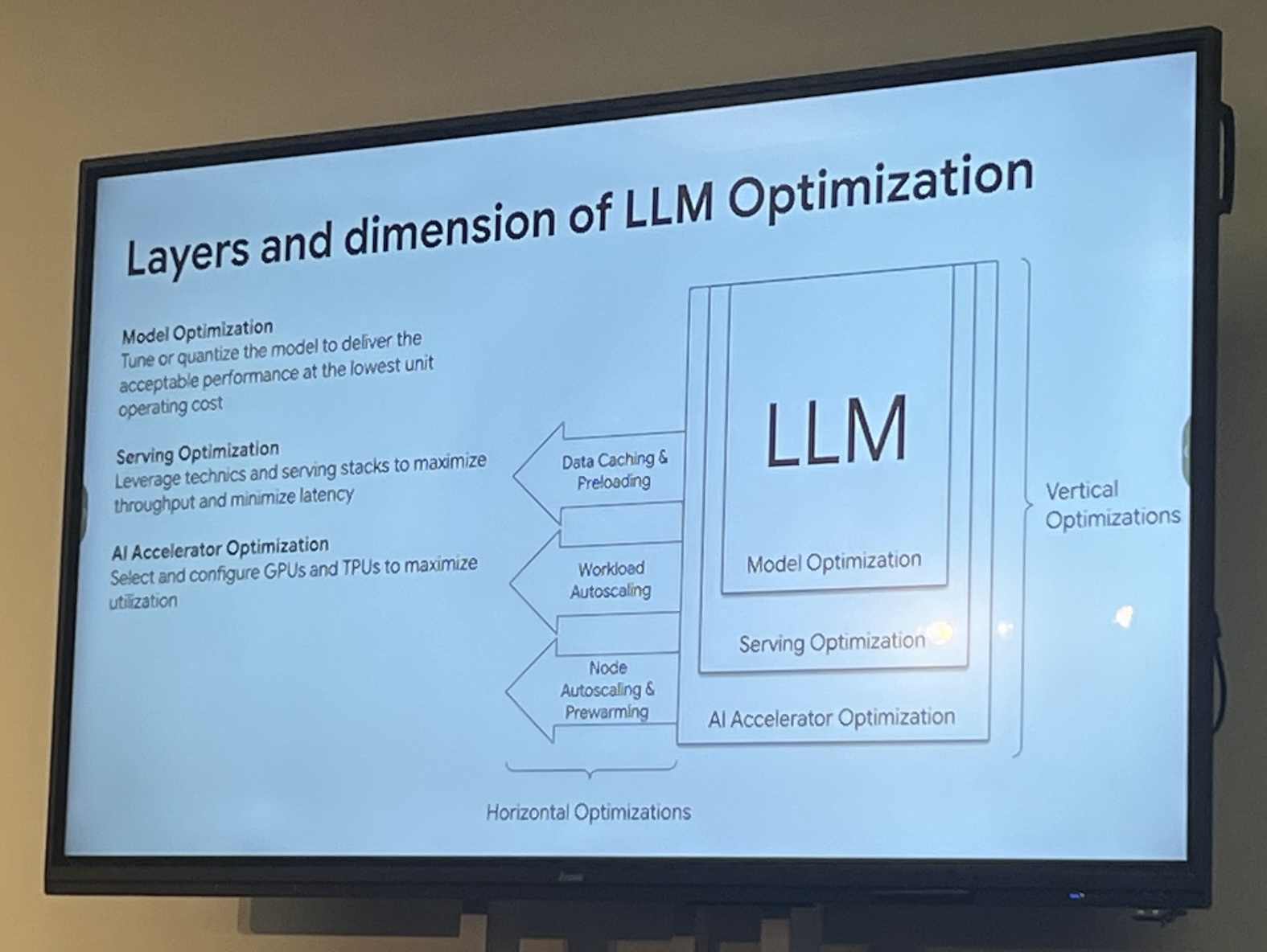
A lot of new features and improvements in GKE are driven by AI workloads and their unique challenges compared to traditional workloads, including but not limited to improved scalability, enhanced security features and finally better integration with AI tools as cluster administrators.
GKE’s roadmap is ambitious and driven by the latest needs that AI has brought to the industry, with a strong focus on making it easier for platform administrators to manage and scale their clusters still while ensuring security and fair sharing of resources between workloads (whether they’re AI or not).
GKE’s direction is clear:
Make a self-managing, self-healing, and intent-driven platform for distributed systems, empowering users to manage fleets of clusters, eliminating the need for Kubernetes expertise.
They even mentioned the term “node-as-a-detail” which perfectly captures the vision of abstracting away the complexities of managing individual nodes in a cluster, allowing developers and admins to focus on their applications and workloads rather than the underlying infrastructure.
CustomComputeClass

Kubecon + CloudNativeCon Europe 2026
The conference opened on tuesday morning with a keynote setting the tone for the rest of the event: announcing nvidia as a new platinum sponsor of the CNCF, and then donating their DRA driver for GPUs to the CNCF. Kubernetes already is the de facto standard for orchestrating distributed systems, and with AI workloads becoming increasingly important, this is a significant step towards ensuring that Kubernetes can effectively support AI workloads in the future.
Another highlight of the keynote was this number: over 80% of companies in the world are using Kubernetes in production, and 66% of companies running GenAI workloads are using Kubernetes to do so.
This can be explained by the fact that Kubernetes provides a powerful and flexible platform for managing and scaling any distributed system, and AI workloads are no exception. Kubernetes’ ability to abstract away the complexities of managing infrastructure and provide a consistent API for deploying and managing applications makes it an ideal choice for companies looking to leverage AI in their operations.
The event was dominated by discussions around AI and its integration with cloud-native technologies, showcasing how AI is transforming the way we build, deploy, and manage applications in the cloud.
Whether you were interested in the latest advancements in AI, security, platform-building, Kubernetes contributions, or the future of cloud-native technologies, there was something for everyone at Kubecon + CloudNativeCon Europe 2026.
I decided to embrace the omnipresent AI theme and attended sessions that focused on how AI is being integrated into cloud-native technologies, the challenges and opportunities it presents.
Training AI models at scale and inferencing AI models in production are two totally different things, and both present unique challenges that the community is actively working to address. I followed sessions on training AI models out of curiosity and to get a better understanding of the challenges involved, but frankly I believe most of my future work will be around inferencing AI models in production, which is a much more common use case for the majority of companies.
AI model Inference on Kubernetes
Inference presents many challenges:
At the workload level:
- Right from the start, your workloads are going to be very large and resource intensive.
Where you would typically request like a couple CPU cores and maybe a few Gigabytes of memory for a web application, you will run into requesting dozens of cores and tens or hundreds of GBs of memory for an AI model inference workload and of course you also need GPUs, or accelerators as they are more commonly refered as. To serve an AI model you need an inference server, which is a piece of software that takes care of loading the model and exposing an API for serving predictions. That piece of software typically orchestrates the several stages it takes to decode the prompt and generate the answer, then stream it back to the client, which means that the response is not sent all at once but rather in chunks as the inference server generates them. Exemple of inference engines include llm-d, vllm, or sglang. They are already a few GBs in size by themselves, without any model included. So your container images easily reach tens of GBs, which is not something we are used to in the world of cloud-native applications. This has implications on how you build and manage your container images, how you handle updates and rollouts, and the lifecycle of your nodes in general. - AI models are often very large, and loading them into memory can take a significant amount of time. This can lead to increased latency for the first few requests as the model is being loaded, which is not ideal for production environments where low latency is crucial.
- AI inference workloads can be highly demanding in terms of resource requirements, which can make it difficult to effectively manage scarce resources in a Kubernetes cluster. Accelerators are highly sought after and not always available in large quantities, which means that you need to be able to efficiently share them between workloads and ensure that they are being used effectively.
DynamicResourcesAllocation is a concept that is being explored to address the challenges of managing resources for AI inference workloads in Kubernetes. It involves Admins setting ResourceSlices in advance just like they would create PersistentVolume, then claiming these Slices at deployment time to dynamically allocate resources to workloads based on their current needs and the availability of resources in the cluster.
- Right from the start, your workloads are going to be very large and resource intensive.
At the cluster level:
- Managing and scaling AI inference workloads in a Kubernetes cluster can be complex, especially when dealing with large models and high demand. You need to be able to efficiently schedule and manage your resources.
- Autoscaling behaves differently for AI inference workloads compared to traditional workloads. Instead of autoscaling based on common metrics like CPU and memory usage, you may need to autoscale based on more specific metrics related to the performance of the inference server, such as the number of requests being processed or the latency of responses.
- The Node lifecycle becomes a critical aspect to consider when running AI inference workloads in Kubernetes. You need to be able to efficiently manage the lifecycle of your nodes to ensure that they are available when needed and that they can be quickly provisioned and deprovisioned as demand fluctuates. Moreover you have the rethink the way you define readiness for your nodes, with AI workloads images being so large, it can take a long time for a node to pull the image after it has been provisioned, thus delaying the time it takes for the node to become ready and start serving traffic. An effort to address these challenges is the current development of the Capacity Buffers API allowing cluster administrators to define buffer capacity for specific resources in their cluster to circumvent the use of balloon pod overprovisioning. Capacity Buffers defines warm and active standby nodes that are kept ready to join the cluster at a lower cost than regular nodes.
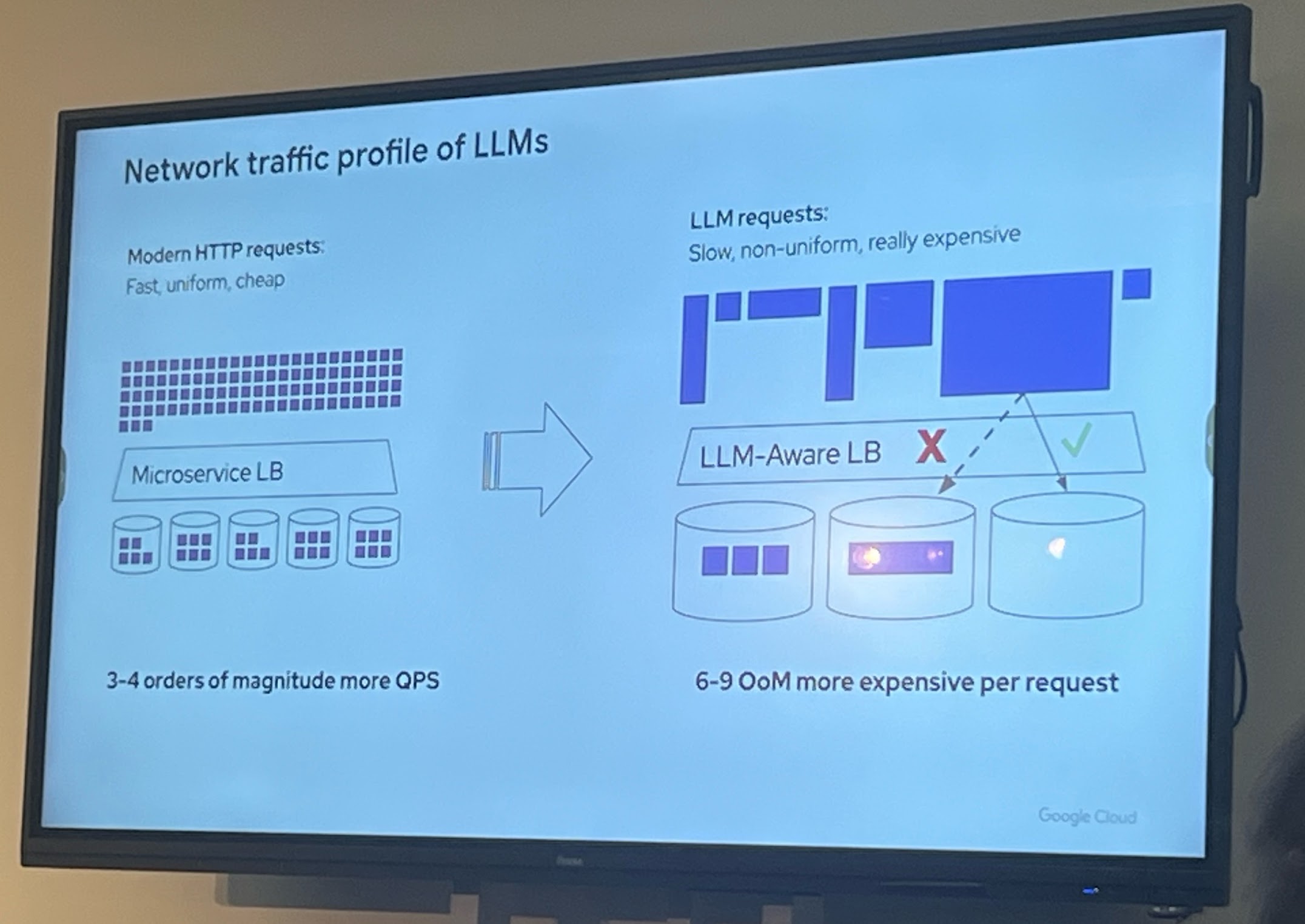
At the exposition layer:
- Exposing AI inference workloads to end-users can also present challenges, especially when dealing with high demand and the need for low latency. You need to be able to efficiently route traffic to the appropriate inference servers, manage load balancing, and ensure that the system can handle spikes in traffic without degrading performance.
- As the successor to Ingress, the Gateway API is receiving an extension called the Inference Extension (GAIE). The GAIE is designed to address the specific challenges of exposing AI inference workloads in Kubernetes, providing features such as support for streaming responses, improved load balancing for AI workloads, and better integration with AI inference engines. InferencePool, InferencePooObjective, Endpoint Picker are some of the new concepts introduced by the GAIE to help manage and route traffic to AI inference workloads more effectively.
Data sovereignty in Europe
With the conference being held in Amsterdam, there was a strong focus on data sovereignty and the unique challenges that European companies face when it comes to managing and processing data in the cloud.
The European Union has strict regulations around data privacy and security, which means that companies operating in Europe need to be particularly mindful of how they manage and process data in the cloud, especially now with the Cyber Resilience Act (CRA) coming into effect in 2027.
The CRA is a new regulation that aims to enhance the cybersecurity of products and services in the European Union. It will require companies to implement robust security measures to protect against cyber threats and ensure the resilience of their products and services. This has significant implications for companies operating in the cloud, as they will need to ensure that their cloud infrastructure and services comply with the CRA’s requirements.
In practice, Kubernetes and the cloud native landscape are a good fit for companies looking to comply with the CRA, as they provide flexible solutions for managing and processing data in the cloud that can be customized to meet the specific needs of each company.While also offering robust security features and benefiting from updates from all other CNCF end user companies that are also looking to comply with the CRA.
There were several sessions that focused on best practices for managing data in the cloud while ensuring compliance with European regulations, as well as discussions around the latest advancements in cloud-native technologies that can help companies meet these challenges.
Some very interesting resources to check out on this topic include the CNCF Architecture Reference, which provides feedback and exemples from companies that have already implemented solutions to comply with the CRA, and the LFX Insights project, because over 200 projects are under the Linux Foundation’s umbrella, and it is increasly hard to keep track of all the advancements and updates across all these projects, so LFX Insights is a great resource to stay up to date with the latest developments in the cloud-native ecosystem.
Conclusion
Attending Kubecon + CloudNativeCon Europe 2026 was an enriching experience that provided valuable insights into the cloud-native ecosystem. The focus on AI and its integration with cloud-native technologies highlighted the transformative impact of AI on the industry.
References
[DynamicResourceAllocation]: https://kubernetes.io/docs/concepts/scheduling-eviction/dynamic-resource-allocation/
[gateway-api-inference-extension]: https://gateway-api-inference-extension.sigs.k8s.io/
[capacity-buffers-api]: https://docs.google.com/document/d/1bcct-luMPP51YAeUhVuFV7MIXud5wqHsVBDah9WuKeo/edit?tab=t.0#heading=h.kgde2rz09cn8
Inference Engines:
[llm-d]: https://llm-d.ai/
[vllm]: https://docs.vllm.ai/en/latest/
[sglang]: https://www.sglang.io/
[lfx-insights-llmd]: https://insights.linuxfoundation.org/project/llm-d
[cncf-architecture-reference]: https://architecture.cncf.io/architectures
[Cyber Resilience Act]: https://digital-strategy.ec.europa.eu/en/policies/cyber-resilience-act
